Incremental Sonar™ Analysis
- Michael Rüegg
- Monica Rüegg
- Caroline Trink (Unlicensed)
Sonar™ source code analysis can take a significant amount of time for large projects. Longer build times are inconvenient for short living branches like hotfix- or feature branches. Incremental Sonar™ Analysis reduces the analysis time by restricting the analyzed files to the changed files in a pull request.
Include Code Quality for Bamboo uses the `sonar.inclusions` parameter to restrict the analyzed files. You can read more about restricting the analysis scope in the SonarQube™ documentation.
The main benefits of Incremental Sonar™ Analysis are
- a shorter analysis time
- it is useful for both the community- and the commercial editions of SonarQube™.
While the pull request analysis in commercial SonarQube™ editions has similar results (only showing issues in changed files) it analyses all files on the branch which can take a long time.
Q: Is the coverage information impacted by incremental mode?
No. As long as the Sonar™ scanner is able to find the coverage result file, SonarQube™ uses it to generate coverage information.
Q: What are the drawbacks of Incremental mode?
- Because the incremental mode is restricted to the new and changed files of a pull request, Sonar™ statistics are not representable for the complete branch anymore. We recommend that you use it for short-lived feature and bug fix branches only. Include Code Quality for Bamboo and Include Code Quality for Bitbucket support this by a regular expression for which branches to apply this mode to.
- The accuracy of the analysis can be reduced with incremental mode because there could be false negatives (e.g. when you deprecate a method in file A.java and this method is used in file B.java which is not part of the pull request diff, no issue will be created for the deprecated method usage in file B.java).
Required Configurations in Bamboo
For Bamboo, we provide special support with our Include Code Quality for Bamboo app.
When you have installed the app on your Bamboo, follow the steps here: Incremental mode for Pull Requests
Required Configurations in Jenkins
To trigger a Jenkins build for your pull requests, you have to use a Bitbucket Server plug-in that triggers a build when a pull request is created or updated (e.g., when you push changes). We recommend the plug-in Pull Request Notifier for Bitbucket or Webhook to Jenkins for Bitbucket for this.
We show you the configuration for Pull Request Notifier for Bitbucket here. The configuration is similar for Webhook to Jenkins for Bitbucket (you just have to make sure that the PULL_REQUEST_ID env variable is set).
Either globally or in the repositories you want to use it, you have to configure the Jenkins URL (including the parameter PULL_REQUEST_ID which we need in the next step to get diff with the new and changed files), the pull request events you want to trigger a new build for and more details in the Pull Request Notifier configuration:
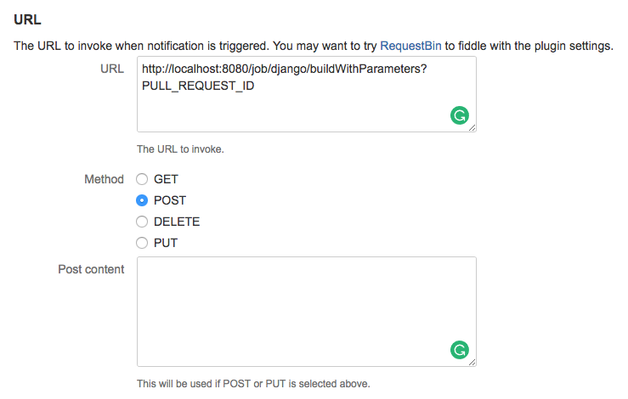
If you are using CSRF protection in Jenkins, you also have to configure a few more settings. For details, please follow these instructions.
Using Jenkinsfile
For Jenkinsfile, we recommend the following code to pass the sonar.inclusions parameter with the list of new and changed files to the Sonar™ analysis:
import groovy.json.JsonSlurperClassic
def toRelativePathInModule(File current, File startingPoint, File workingDir) {
if (current == null) return null
if (current.isDirectory()) {
def sonarFile = current.listFiles().find { it.getName() == 'sonar-project.properties' || it.getName() == 'pom.xml' }
if (sonarFile) {
return sonarFile.getParentFile().toURI().relativize(startingPoint.toURI()).getPath()
} else if (current == workingDir) {
return workingDir.toURI().relativize(startingPoint.toURI()).getPath()
}
}
return toRelativePathInModule(current.getParentFile(), startingPoint, workingDir)
}
if (!env.PULL_REQUEST_ID) {
error("PULL_REQUEST_ID not set")
}
def pullRequestId = env.PULL_REQUEST_ID
//TODO change variables here!
def bitbucketServer = "http://localhost:7990/bitbucket"
def projectKey = "PROJECT_1"
def repoSlug = "maven-sub-modules"
def pullRequestDiffUrl = new URL(
"$bitbucketServer/rest/api/1.0/projects/$projectKey/repos/$repoSlug/pull-requests/$pullRequestId/changes?limit=9999"
)
//use either personal access token (available since Bitbucket 5.5.0) or basic auth
//TODO use personal access token:
def personalAccessToken = "XXX" // can be created under Bitbucket user -> manage account -> personal access token
def withPersonalAccessToken = ["Authorization": "Bearer $personalAccessToken"]
//TODO or use basic authentication
//def authString = "admin:admin".getBytes().encodeBase64().toString()
//def withBasicAuth = ["Authorization": "Basic ${authString}"]
def pullRequestDiff = new JsonSlurperClassic().parse(pullRequestDiffUrl.newReader(requestProperties: withPersonalAccessToken)).values
node {
def workspace = env.WORKSPACE
def files = pullRequestDiff.collect {
toRelativePathInModule(new File(workspace, it.path.toString), new File(workspace, it.path.toString), new File(workspace))
}.join(",")
stage('SCM') {
git url: 'http://admin@localhost:7990/bitbucket/scm/project_1/maven-sub-modules.git'
}
stage('SonarQube analysis') {
withSonarQubeEnv('sonar') {
sh "mvn clean package sonar:sonar -Dsonar.inclusions=$files"
}
}
stage("Quality Gate"){
timeout(time: 30, unit: 'MINUTES') {
def qg = waitForQualityGate()
if (qg.status != 'OK') {
error "Pipeline aborted due to quality gate failure: ${qg.status}"
}
}
}
}
Using freestyle jobs
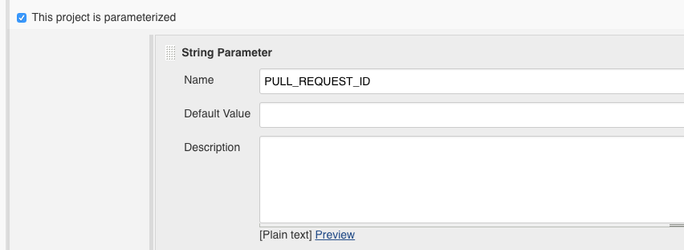
To use incremental analysis with a freestyle job, you need to get the pull request details from the passed PULL_REQUEST_ID to get the list of new and changed files and to pass this to the sonar.inclusions parameter. For this, you have to enable that your Jenkins build is parameterized:
Then, we use Bitbucket's REST interface to get the diff of the pull request and store it in a file so that we can use it later together with the EnvInject plug-in:
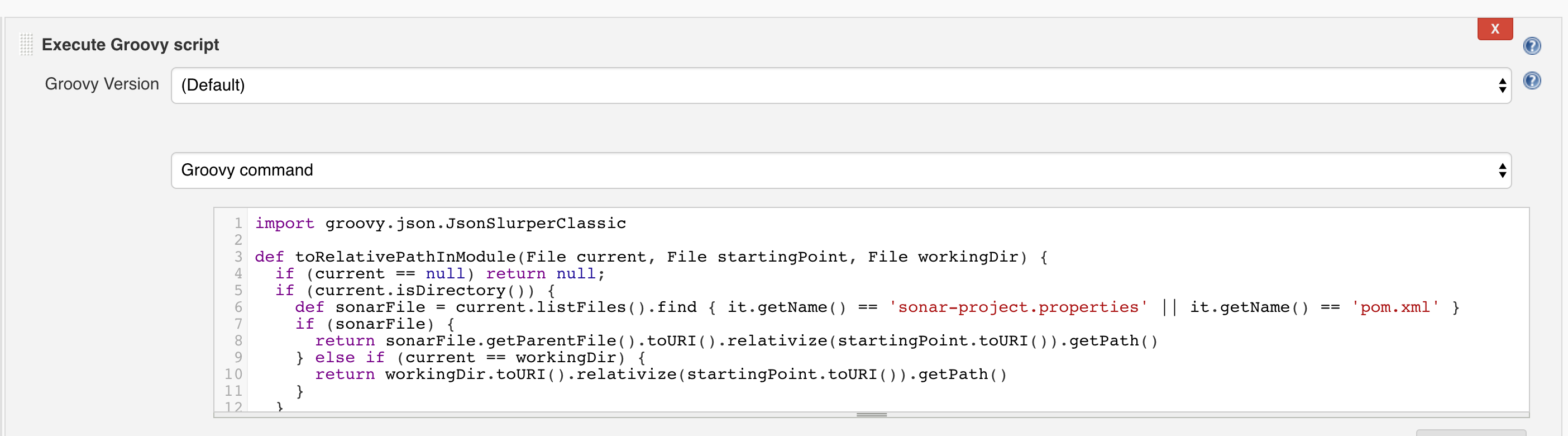
Here's the complete Groovy script code:
import groovy.json.JsonSlurperClassic
def toRelativePathInModule(File current, File startingPoint, File workingDir) {
if (current == null) return null;
if (current.isDirectory()) {
def sonarFile = current.listFiles().find { it.getName() == 'sonar-project.properties' || it.getName() == 'pom.xml' }
if (sonarFile) {
return sonarFile.getParentFile().toURI().relativize(startingPoint.toURI()).getPath()
} else if (current == workingDir) {
return workingDir.toURI().relativize(startingPoint.toURI()).getPath()
}
}
return toRelativePathInModule(current.getParentFile(), startingPoint, workingDir)
}
if (!env.PULL_REQUEST_ID) {
error("PULL_REQUEST_ID not set")
}
def pullRequestId = env.PULL_REQUEST_ID
def bitbucketServer = "http://localhost:7990/bitbucket"
def projectKey = "PROJECT_1"
def repoSlug = "maven-sub-modules"
def personalAccessToken = "XXX"
def pullRequestDiffUrl = new URL(
"$bitbucketServer/rest/api/1.0/projects/$projectKey/repos/$repoSlug/pull-requests/$pullRequestId/changes?limit=9999"
)
def withPersonalAccessToken = ["Authorization": "Bearer $personalAccessToken"]
def pullRequestDiff = new JsonSlurperClassic().parse(pullRequestDiffUrl.newReader(requestProperties: withPersonalAccessToken)).values
//use either personal access token (available since Bitbucket 5.5.0) or basic auth
//TODO use personal access token:
def personalAccessToken = "XXX" // can be created under Bitbucket user -> manage account -> personal access token
def withPersonalAccessToken = ["Authorization": "Bearer $personalAccessToken"]
//TODO or use basic authentication
//def authString = "admin:admin".getBytes().encodeBase64().toString()
//def withBasicAuth = ["Authorization": "Basic ${authString}"]
def pullRequestDiff = new JsonSlurperClassic().parse(pullRequestDiffConn.newReader(requestProperties: withPersonalAccessToken)).values
def files = pullRequestDiff.collect {
toRelativePathInModule(new File(workspace, it.path.toString), new File(workspace, it.path.toString), new File(workspace))
}.join(",")
f = new File('sonar-diff.txt')
f.write("SONAR_DIFF=$files")
Then, please add the EnvInject task to your build job:

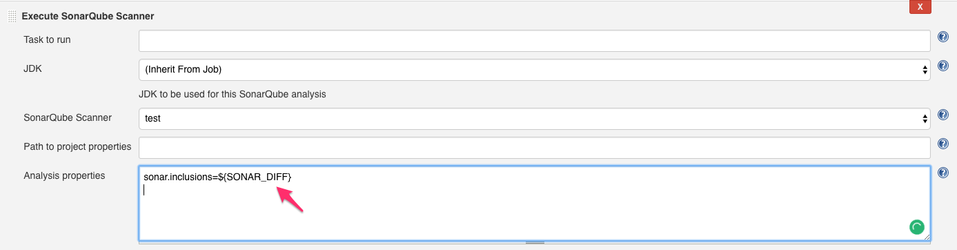
Finally, we can execute SonarQube™ with the sonar.inclusions parameter by using the environment variable from the EnvInject plug-in:
Verification that everything works
With the above configurations, you can restrict your SonarQube™ analysis to the new and changed files only and you will have a super-fast analysis for your pull request. To see if your configuration works, you can check your build log that SonarQube™ will only analyze the files of your pull request (search for "Included sources"):

SONAR™, SONARQUBE™ and SONARCLOUD™ are independent and trademarked products and services of SonarSource SA: see sonarsource.com, sonarqube.org, sonarcloud.io.